

概要 Hyper-Space
Hyper(HyperSpace)について
Hyper(HyperSpace)とは?
Hyper(HyperSpace)は、弾力的互換性のあるクラウドネイティブ検索データベースです。独自のカスタムコンピューティングパワーを活用し、あらゆる種類の検索をいつでも、どんな規模でも、パフォーマンスと一貫性を損なわず実行できます。
性能重視のエンジニアによって開発され、従来のソフトウェアベースソリューションの限界を超え、データ集約型アプリケーションにおいて比類なき検索パフォーマンスを提供します。
Hyper(HyperSpace)を使う理由
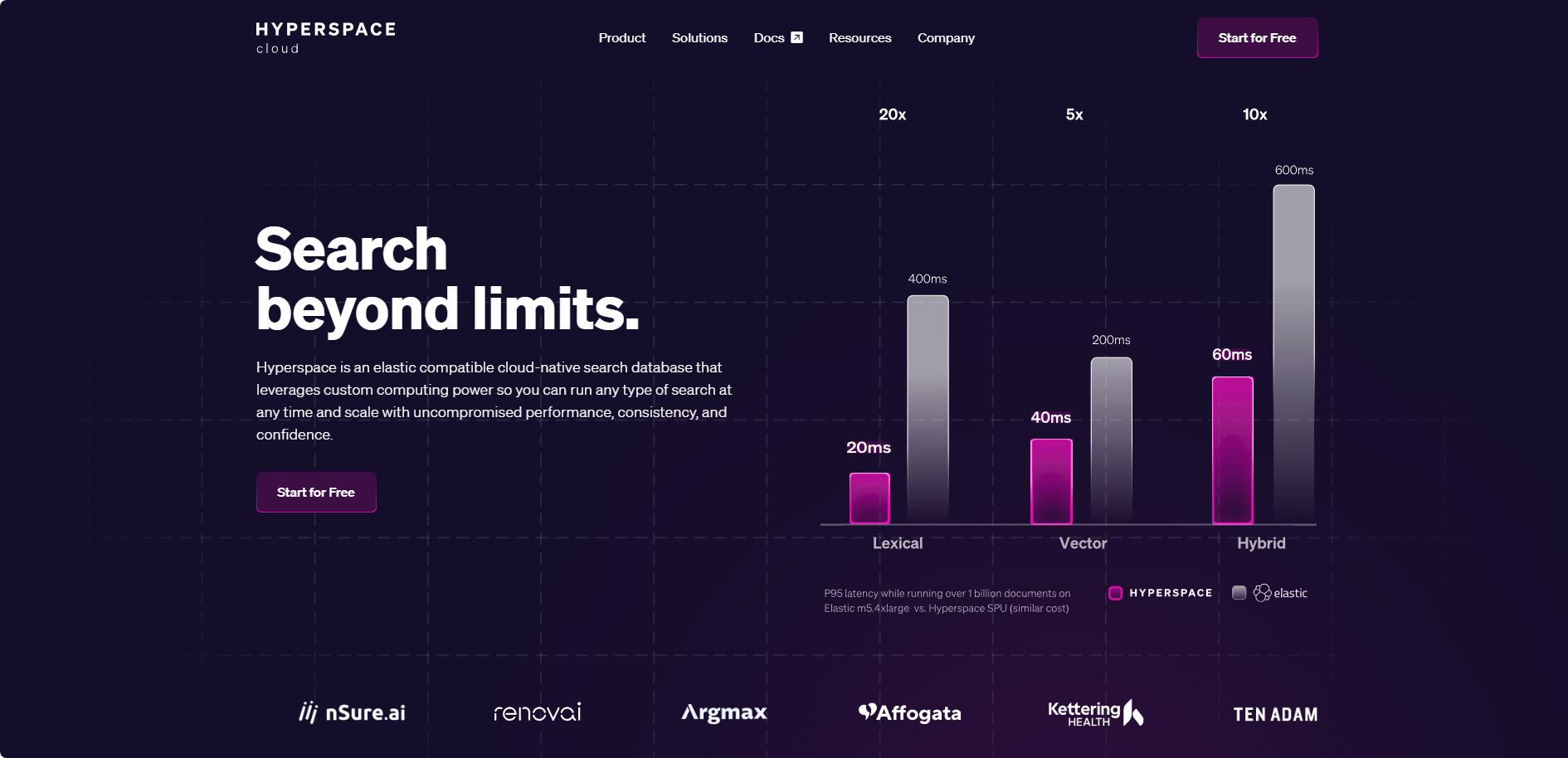
他の検索データベースが10倍の性能向上を約束するのに対し、Hyperは実際にそれを実現します。
ベクトル検索と語彙検索を組み合わせ、メタデータフィルタリング、集計、TF-IDFなどの機能を活用し、より深く柔軟な検索を実現。10億件規模のデータを半分のコストで処理し、10ミリ秒以下の低レイテンシーを実現します。
対象となるユーザー
- 大規模ECプラットフォーム
- 不正検出・リスク管理企業
- メディア・コンテンツプラットフォーム
- 金融・決済システム
- エンタープライズ開発チーム
- ビッグデータ処理企業
価格体系
Hyper(HyperSpace)は、無料トライアル、従量課金、エンタープライズプランを提供します。
免責事項:価格情報は最新のものではない可能性があります。最も正確で最新の価格詳細を取得するには、当該AIツールの公式ウェブサイトをご確認ください。
- 無料トライアル 機能体験、小規模データテスト、導入検証、開発環境
- 従量課金プラン 検索量・データサイズに応じた課金、弾力的スケーリング、標準サポート
- エンタープライズプラン 個別見積もり、専用環境、SLA保証、専任サポート、カスタム開発
主な機能
10倍高速な検索
独自のFPGAベースチップにより、従来のソリューションをはるかに超える検索速度を実現。
ハイブリッド検索
- ベクトル検索と語彙検索を融合
- メタデータフィルタリング・集計・TF-IDF対応
- 高精度な類似度クエリを実行
弾力的スケーリング
0から10億件までシームレスにスケール、データベースコストを50%削減、SLAを容易に達成。
高スループット
5倍の処理能力、4倍のデータ取り込み速度を実現、リアルタイムデータ処理に最適。
高可用性
クラウドネイティブ設計、高信頼性、シームレスな統合、エンタープライズセキュリティ。
Elastic互換性
既存のElasticワークロードを簡単に移行、学習コスト不要、迅速な導入。
まとめ
Hyper(HyperSpace)は、カスタムコンピューティングパワーを活用したクラウドネイティブ検索データベースです。10倍高速、ハイブリッド検索、弾力的スケーリング、高スループット、Elastic互換が特徴で、大規模データ検索を革新します。











