

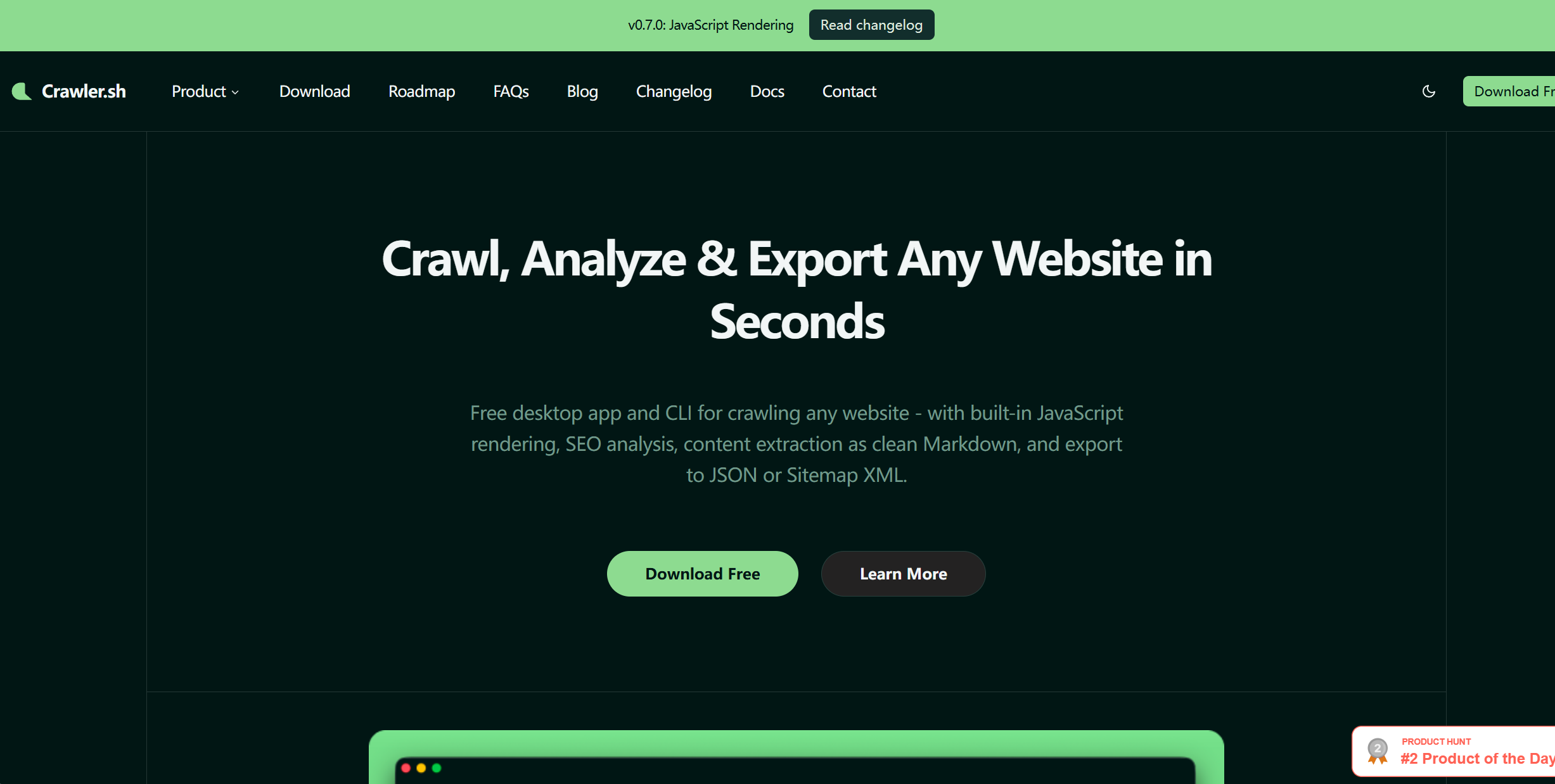
概要 crawler.sh
コマンドラインで動作する軽量Webクローラー・スクレイピングツール
シンプルなコマンド操作でWebサイトのクロール・データ抽出・解析を実行

crawler.shの主な特徴
超軽量・高速動作
軽量な設計でリソース消費が少なく、高速なWebクロールとデータ抽出を実現します。
コマンドライン操作
直感的なシェルコマンドで操作し、プログラミング不要でデータ収集が可能です。
JSON/CSV出力
抽出したデータをJSONやCSV形式で出力し、解析やシステム連携に活用できます。
コア機能

高速Webクローリング
指定したURLから再帰的にページをクロールし、コンテンツやリンクを自動的に収集します。
クロール深度やドメイン制限の設定が可能で、効率的なデータ収集をサポートします。

セレクター指定データ抽出
CSSセレクターやXPathを使用して、必要なテキスト・画像・URLなどを精密に抽出可能です。
動的コンテンツにも対応し、JavaScriptレンダリング後のデータも取得できます。

自動化とシステム連携
シェルスクリプトやcronと連携し、定期的なクロールを自動実行できます。
他のツールやデータベースと連携し、収集したデータをシームレスに活用可能です。
料金プラン
フリー
0USD/月
- 月間100回までのクロール実行
- 基本的なデータ抽出機能
- CSV/JSON出力対応
- 個人利用・非商用向け
プロ
29USD/月
- 無制限クロール実行
- JavaScript動的コンテンツ対応
- 並列処理・高速モード
- 商用利用ライセンス
- 優先サポート対応
活用シーン
Webデータ収集業務
価格・商品情報調査
ニュース・記事収集
エンジニア解析業務
マーケットリサーチ
データ分析基盤構築
自動化データ収集
中小企業業務効率化






